Автоассоциативная
сеть. Сеть (обычно многослойный
персептрон), предназначенная для
воспроизведения на выходе входной информации
после "сжатия" данных в промежуточном слое,
имеющем меньшую размерность. Используется для
сжатия информации и понижения размерности
данных (Fausett, 1994; Bishop, 1995).
Автоматический
конструктор сети. Реализованный в пакете Нейронные
сети STATISTICA эвристический алгоритм, который
опытным путем находит архитектуру сети,
соответствующую имеющимся данным.
Аддитивная
сезонность, демпфированный тренд. В этой
модели анализа временных
рядов прогнозы простого экспоненциального
сглаживания "улучшаются" демпфированным
трендом [сглаживается независимо с параметром 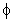 (фи)] и аддитивной
сезонной компонентой (сглаживается с параметром
(фи)] и аддитивной
сезонной компонентой (сглаживается с параметром 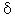 ). Например, пусть вы
прогнозируете процент семей, имеющих данное
электронное устройство (например,
видеомагнитофон). Каждый год доля семей, имеющих
собственный видеомагнитофон, увеличивается,
однако этот тренд демпфированный, иными словами,
возрастание тренда постепенно уменьшается, так
как с течением времени рынок насыщается.
Дополнительно, имеется сезонная составляющая
покупательского спроса (спрос меньше в летние
месяцы и больше в декабре). Эта сезонная
компонента может быть аддитивной; например,
относительно стабильное число семей решают
купить видеомагнитофон в декабре.
). Например, пусть вы
прогнозируете процент семей, имеющих данное
электронное устройство (например,
видеомагнитофон). Каждый год доля семей, имеющих
собственный видеомагнитофон, увеличивается,
однако этот тренд демпфированный, иными словами,
возрастание тренда постепенно уменьшается, так
как с течением времени рынок насыщается.
Дополнительно, имеется сезонная составляющая
покупательского спроса (спрос меньше в летние
месяцы и больше в декабре). Эта сезонная
компонента может быть аддитивной; например,
относительно стабильное число семей решают
купить видеомагнитофон в декабре.
Для вычисления сглаженных значений в первом
сезоне необходимы начальные значения сезонных
компонент. По умолчанию модуль Временные ряды
оценит эти значения (для всех моделей с сезонной
компонентой) из данных с помощью Классической
сезонной декомпозиции. Далее S0 и T0
(начальный тренд) вычисляются по формуле:
T0 = (1/ )*(Mk-M1)/[(k-1)*p]
)*(Mk-M1)/[(k-1)*p]
где
- параметр
сглаживания
k - число полных сезонных
циклов
Mk - среднее на
последнем сезонном цикле
M1 - среднее на
первом сезонном цикле
p - длина сезонного
цикла
и S0 = M1 - p*T0/2
Аддитивная
сезонность, линейный тренд. В этой модели
анализа временных рядов в
прогнозе учитывается как линейный тренд
[сглаживаемый независимо с параметром 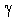 (гамма)], так и
аддитивная сезонная компонента [с параметром (дельта)]. Например,
пусть вы прогнозируете бюджет для удаления
снежных заносов в определенном районе. Имеется
трендовая компонента бюджета (определяемый
размером района, т.к. имеется устойчивый
возрастающий тренд увеличений затрат в
зависимости от размера района). В то же время,
очевидно, в ряде имеется сезонная компонента,
отражающая различную вероятность выпадения
снега в разные месяцы года. Сезонная компонента
может быть аддитивной. Это означает, что
фиксированное количество дополнительных
средств необходимо в зимние месяцы или (см. ниже)
мультипликативной, когда расходы в зимние месяцы
должны быть увеличены в определенное число раз,
например, в 1.4 раза.
(гамма)], так и
аддитивная сезонная компонента [с параметром (дельта)]. Например,
пусть вы прогнозируете бюджет для удаления
снежных заносов в определенном районе. Имеется
трендовая компонента бюджета (определяемый
размером района, т.к. имеется устойчивый
возрастающий тренд увеличений затрат в
зависимости от размера района). В то же время,
очевидно, в ряде имеется сезонная компонента,
отражающая различную вероятность выпадения
снега в разные месяцы года. Сезонная компонента
может быть аддитивной. Это означает, что
фиксированное количество дополнительных
средств необходимо в зимние месяцы или (см. ниже)
мультипликативной, когда расходы в зимние месяцы
должны быть увеличены в определенное число раз,
например, в 1.4 раза.
Для вычисления сглаженных значений в первом
сезоне необходимы начальные значения сезонных
компонент. По умолчанию модуль Временные ряды
оценит эти значения (для всех моделей с сезонной
компонентой) из данных с помощью Классической
сезонной декомпозиции. Далее S0 и T0
(начальный тренд) вычисляются по формуле:
T0 = (Mk-M1)/((k-1)*p
где
k число полных
сезонных циклов
Mk среднее на
последнем сезонном цикле
M1 среднее на первом
сезонном цикле
p длина сезонного
цикла
и S0 = M1 - T0/2
Аддитивная
сезонность, с исключенным трендом. Эта
модель в анализе временных
рядов частично эквивалентна модели простого
экспоненциального сглаживания. Однако,
дополнительно в каждом прогнозе учитывается
аддитивная сезонная компонента, которая
сглаживается независимо (см. Параметр сезонного
сглаживания ).
Эта модель могла бы, например, подойти для
прогноза месячных ожидаемых осадков. Количество
осадков достаточно стабильно из года в год,
изменяется очень медленно. В то же время имеется
отчетливая сезонность ("сезоны дождей"),
которая также изменяется мало из года в год.
Для вычисления сглаженных значений в первом
сезоне необходимы начальные значения сезонных
компонент. По умолчанию, модуль Временные ряды
оценит эти значения (для всех моделей с сезонной
компонентой) из данных с помощью Классической
сезонной декомпозиции. Заметим, что по умолчанию
начальное значение S0 будет вычислено,
как среднее наблюдений на полном сезонном цикле.
Аддитивная
сезонность, экспоненциальный тренд. В этой
модели анализа временных
рядов простое экспоненциальное сглаживание
применяется для обеих компонент:
экспоненциального тренда [сглаживание
производится с параметром (гамма)] и аддитивной сезонной
компоненты [сглаживается с параметром (дельта)]. Например,
пусть вы прогнозируете месячный доход курортной
зоны. Каждый год доход может увеличиваться на
определенный процент или в определенное число
раз (что приводит к экспоненциальному тренду).
Кроме того, в данных, возможно, присутствует
аддитивная сезонная компонента, например,
определенный фиксированный (и медленно
меняющийся) размер дохода добавляется во время
рождественских праздников.
Для вычисления сглаженных значений в первом
сезоне необходимы начальные значения сезонных
компонент. По умолчанию модуль Временные ряды
оценит эти значения (для всех моделей с сезонной
компонентой) из данных с помощью Классической
сезонной декомпозиции. Далее S0 и T0
(начальный тренд) вычисляются по формуле:
T0 = exp((log(Mk) - log(M1))/p)
где
k число полных сезонных
циклов
Mk среднее на
последнем сезонном цикле
M1 среднее на первом
сезонном цикле
p длина сезонного цикла
и S0 = exp(log(M1) - p*log(T0)/2)
Алгоритм. В
противоположность эвристикам
(которые содержат общие рекомендации, основанные
на статистической очевидности и теоретических
рассуждениях), алгоритмы являются полностью
определенными, конечными наборами шагов,
операций или процедур, которые приводят к
конкретному результату. Например, за небольшим
исключением, все компьютерные программы,
математические формулы, и (в идеале) все
медицинские и кулинарные рецепты являются алгоритмами.
См. также разделы Добыча
данных, Нейронные сети,
Эвристики.
Алгоритм К ближайших
соседей. Алгоритм выбора отклонений для
радиальных элементов. Каждое отклонение равно
усредненному расстоянию до K ближайших
точек.
См. раздел Нейронные сети.
Алгоритм К
средних. Алгоритм, предназначенный для
выбора K центров, представляющих кластеры в N
точках (K<N). Отправляясь от случайной
выборки из N точек, расположение центров
кластеров последовательно корректируется таким
образом, чтобы каждая из N точек относилась
ровно к одному из K кластеров и центр каждого
кластера совпадал с центром тяжести относящихся
к нему точек (Bishop, 1995).
См. разделы Кластерный
анализ, Нейронные сети.
Алгоритмы минимизации
функции. Алгоритмы,
используемые для поиска минимума, в частности, в нелинейном оценивании,
при этом здесь минимизируется заданная функция потерь.
Алгоритмы
минимизации функций, свободные от производных.
В нелинейном оценивании
предлагается несколько основных алгоритмов
минимизации функций, использующих различные
стратегии поиска (которые не зависят от
производных второго порядка). Эти стратегии
наиболее эффективны при минимизации функция потерь, имеющей локальные минимумы.
Анализ
выживаемости. Анализ выживаемости (разведочный анализ данных
и проверка гипотез) включает описательные методы
для оценивания распределения выборочных времен
жизни, сравнения выживаемости в двух или
нескольких группах, а также опции подгонки
линейных и нелинейных регрессионных моделей к
данным о выживаемости. Характерным аспектом
данных о выживаемости является наличие так
называемых цензурированных
наблюдений, например, наблюдаемых объектов,
которые дожили до определенного момента времени,
а после этого были исключены из наблюдения
(например, пациенты были выписаны из больницы).
Вместо удаления такого наблюдения из множества
изучаемых данных (т.е. необязательной потери
потенциально важной информации), методы анализа
выживаемости позволяют собрать цензурированные
наблюдения и использовать их при проверке
статистической значимости и подгонке модели.
Типичный набор методов анализа выживаемости
включает анализ таблиц
времен жизни, распределения
выживания и оценивание функции выживания Каплана-Мейера, а
также дополнительные методы сравнения
выживаемости в двух или более группах. Наконец, анализ
выживаемости включает использование регрессионных моделей
для оценивания зависимостей между несколькими
непрерывными переменными, содержащими времена
жизни.
Для получения дополнительной информации см.
раздел Анализ выживаемости.
Анализ процессов.
В промышленности анализ процессов
понимается как набор аналитических методов,
которые могут быть использованы для того, чтобы
гарантировать соблюдение норм качества
произведенной продукции. Эти методы включают планы выборочного
контроля, анализ
пригодности, подгонку измерений к негауссовским
распределениям, анализ повторяемости
и воспроизводимости , а также анализ Вейбулла и анализ
времен надежности/отказа.
Для получения дополнительной информации см.
главу Анализ процессов.
Анализ
соответствий. Анализ соответствий -
это раздел статистики, разрабатывающий
описательные/разведочные
методы анализа двухвходовых и многовходовых
таблиц, которые обуславливают некоторую степень
соответствия между строками и столбцами.
Результаты этих методов похожи по своей природе
на методы факторного анализа
и позволяют исследовать структуру группирующих
переменных, включенных в таблицу. Одной из
наиболее общих разновидностей таблиц такого
типа являются двувходовые частотные таблицы
сопряженности (см. например, разделы Основные статистики или Логлинейный анализ).
Для получения дополнительной информации см.
главу Анализ соответствий.
Апостериорные
сравнения. Обычно, получив при проведении дисперсионного анализа
статистически значимое значение F-критерия, мы хотели бы
узнать, какая из групп вызвала этот эффект, т.е.
какие из групп значительно отличаются от других.
Конечно, мы могли бы вычислить
последовательность обычных t-критериев
для сравнения всех возможных пар средних. Однако
такая процедура будет основана на случайности.
Получаемые уровни вероятности будут завышать
значимость различия между средними. Например,
предположим, что мы получили 20 выборок по 10
случайно выбранных чисел каждая, а затем
вычислили 20 средних. После этого возьмем группу
(выборку) с наибольшим средним и сравнить ее с
выборкой с наименьшим средним. t-критерий для
независимых выборок проверяет, являются ли
два средних значимо отличающимися друг от друга,
в предположении, что рассматриваются всего две
выборки. Метод апостериорных сравнений,
наоборот, предполагает наличие более чем двух
выборок. Этот метод используется для проверки
гипотез и разведочного
анализа.
Для получения дополнительной информации см.
раздел Дисперсионный
анализ.
Априорные
вероятности. Задают пропорции классов в
популяции (в задачах классификации), особенно в
тех случаях, когда известно, что эти пропорции
отличаются от пропорций в обучающем множестве.
Используются для модификации обучения вероятностных
нейронных сетей.
См. разделы Нейронные
сети, Дискриминантный
анализ.
Асимметрия.
Асимметрия или коэффициент асимметрии (термин
был впервые введен Пирсоном, 1895) является мерой
несимметричности распределения. Если этот
коэффициент отчетливо отличается от 0,
распределение является асимметричным.
Плотность нормального распределения симметрична относительно
среднего.
Асимметрия = n*M3/[(n-1)*(n-2)* 3]
3]
где
M3 равно 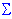 (xi-Среднееx)3
(xi-Среднееx)3
3
стандартное отклонение (сигма),
возведенное в третью степень
n число наблюдений.
См. также раздел Обзор описательных
статистик.
Атрибут (атрибутная
переменная). Другое название для номинальной переменной.